|
résztvevőjét megpróbálja egy, a már feltárt
közösségen kívüli, de a maradék k-1 résztvevővel újra k-klikket alkotó
elemmel lecserélni. A már tovább nem bővíthető, esetlegesen egymással
átfedő közösségek képezik a végeredményt.
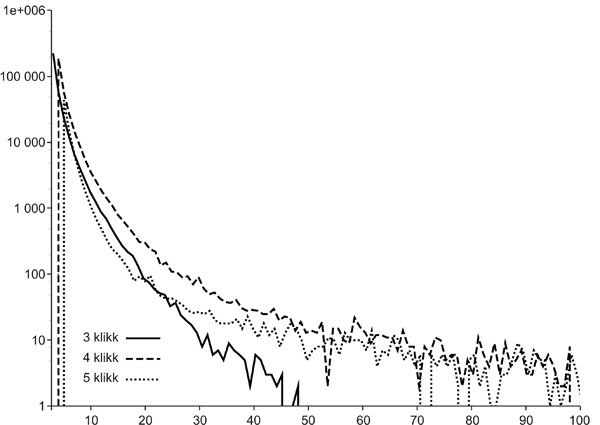
A következőkben a fent vázolt módszer a
6. ábra
nagy hálózatán, illetve általában olyan nagyméretű hálózatokon való
viselkedését mutatjuk be, amelyekben sok sűrű kis közösséget hosszú
nyúlványok kötnek össze. A
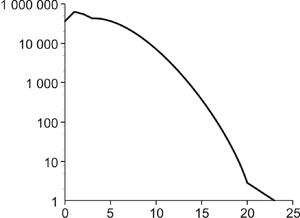
6. ábra felső táblázatában
láthatjuk, hogy a klikkek száma rendkívül magas, és az ezeket kezelő
algoritmus megvalósítása így nem egyszerű. A legnagyobb közösség
mérete 3-klikkek esetében szintén a klikkek nagy száma miatt óriási.
Ugyanakkor a közösségek száma áttekinthetetlenül nagy – ez még
5-klikkek esetén is igaz. Ahogy k növekszik, ugyanakkor csökken a
felhasználható klikkek száma, és egyre kevesebb résztvevőt választunk
bele egyáltalán valamelyik közösségbe. A nyúlványokba tartozó, sűrű
magoktól távolabb eső elemekkel nem tudunk igazán mit kezdeni. Az ábra
alsó részén láthatjuk, hogy a közösségek túlnyomó többsége rendkívül
kicsi, azaz nagyon sok a nagyon sűrű kis csoport.
Spektrál klaszterezés
A spektrál klaszterezés olyan heurisztikák gyűjtőneve, melyek a
hálózat elemeit az első főirányokra vetítik, és a kapott alacsony
dimenziós térben sűrűségalapon keresnek csoportokat. A legjobban
működő módszerek, amint azt a szakirodalom részletesebb elemzésével és
kísérletekkel megmutattuk (Kurucz et al., 2008), egy viszonylag magas,
pár tízdimenziós térbe vetíti a hálózat résztvevőit, és utána tíz
körüli darab csoportot próbál képezni. Siker esetén a kapott
csoportokon a módszer megismételhető, így egy klaszterhierarchia áll
elő.
A spektrál klaszterezés is érzékeny a sűrű magok és
hosszú nyúlványok problémájára. Igen gyakran kimenetként a tagok sűrű
magokba, illetve nyúlványokba tartozás szerinti kettéosztását kapjuk.
A sűrű magok legalább összefüggő csoportot alkotnak, a másik oldal
azonban egymástól izolált apró nyúlványokra bomlik. Ráadásul ezek a
darabkák nagyon erősen kötődnek a másik oldal bizonyos részeihez, egy
utófeldolgozási lépésben tehát ezeket egyenként áthelyezhetjük a
túloldalra, amíg végül visszakapjuk az
eredeti teljes adathalmazt mint egyetlen klasztert.
Az általunk javasolt módszer lényege, hogy a
vetítési dimenziók számát mindaddig növeljük, amíg a nem összefüggő
részek szétosztása után kapott legkisebb és legnagyobb összefüggő
klaszter méreteinek aránya egy küszöb alá nem kerül. Nagyon nehezen
bontható hálózatok esetében a sűrű részek és a nyúlványok összevonását
is alkalmazhatjuk, például Budapest sűrű szociális kapcsolatrendszerét
ilyen módon lehet szétbogozni. Megjegyezzük, hogy a dimenziók számának
növelése nagyon megnöveli a számításigényt, tehát gondos egyensúlyra
kell törekednünk a paraméterek megválasztásakor.
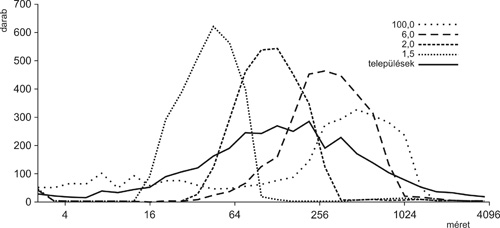
A 7.
ábrán láthatók a spektrál particionálással kapott
eredményeink. Megfigyelhető, hogy a küszöb szigorításával egyre
nagyobbá válik a legnagyobb, tovább nem bontható közösség mérete. Ez
a nagy közösség azonban a kapcsolatokkal túl sűrűn ellátott főváros
következménye, és Budapestet elhagyva már jól kezelhető méreteket
látunk. Az ábra alsó részén a kisebb közösségek darabszámának
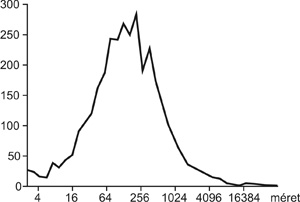
eloszlását is láthatjuk, amelyre rávetítettük az 1. ábra
településméret-eloszlását is. Itt a 2 és 6 közötti küszöbértékek
választása a településméretekhez nagyon hasonló közösség-méreteket
eredményez.
Lemorzsolódás
és hálózaton alapuló kategorizáció
Utolsó alkalmazásunkban megmutatjuk, hogyan aknázható ki a hálózati
kapcsolatokban rejlő információ a churn, azaz az előfizetés
lemondásának előrejelzésében. Kísérletünket a kis adathalmazon
folytatjuk olyan módon, hogy nyolc hónap tanító időszak után négy
hónappal előre, a 12. hónapra adjuk az előrejelzést. Hipotézisünk
szerint, amelyet méréseink igazolnak, az egymással kapcsolatban álló
előfizetők befolyásolják egymás véleményét, és csoportokban együtt
jutnak elhatározásra, hogy előfizetésüket lemondják.
A következőkben bemutatott módszer az ún. félig
felügyelt osztályozás (Zhu, 2005) csoportjába tartozik, amelyben az
ismeretlen, felcímkézetlen egyedek tulajdonságait is hasznosítjuk a
modellépítés során. Ebben a csoportban található az általunk
alkalmazott hálózati elemek osztályozása, amely iteratív tanulási
folyamat. Kezdőlépésként a meglevő forgalmi, előfizetési és
szociodemográfiai adatok alapján meghatározzuk minden résztvevő churn
értékét. Ezután megnézzük minden előfizető esetén a vele kapcsolatban
álló többi előfizető előrejelzett értékét és ezekből újabb jellemzőket
gyártunk, amelyekkel kibővítve, akár több iterációban folytatjuk a
modellépítést. Többféle jellemzőt állítunk elő, amely a szomszédok
churn előrejelzésének c átlagán, illetve kapcsolati erősségekkel
súlyozott c’ átlagán alapulnak. Ezek közül a c’ olyan változata
bizonyul legjobbnak, amely a kevés kapcsolattal rendelkező csúcsokon
„regularizációt” alkalmaz, azaz a semleges átlag felé tolja el a
jellemző értékét.
A tulajdonságok hálózati kapcsolatokon keresztül
történő továbbítása a churn előrejelzés mellett számos további
alkalmazással bír, amelyek között megtalálható az internet
dokumentumainak osztályozása és a bizalom vagy bizalmatlanság
megerősítése. Talán a legfontosabb, a módszert egyik elsőként
alkalmazó terület a web spamszűrés, azaz a kizárólag a
keresőrendszerek találati rangsorának manipulálására létrehozott,
értelmetlen vagy kifejezetten megtévesztő tartalmak fellelése
(Benczúr, 2008). A web spam esetében a továbbítás például azon alapul,
hogy becsületes tartalom elvétve hivatkozik spamre, míg a spam
oldalakra azok egymást erősítő szándékai következtében mindig nagyon
sok spam hivatkozik.
A klasszifikációt kísérletünkben a Weka ún. cost sensitive C4.5
módszerével végeztük a különböző típusú hívások (helyi, távolsági,
csúcsidő, alternatív szolgáltatón keresztüli) összértékeivel mint
jellemzőkkel. Az alap klasszifikátorhoz képest egy lépésben 25%
javulást eredményezett a hálózati információk kihasználása, a második
iteráció azonban már rontott a minőségen. Érdekességként megjegyezzük,
hogy a c’ érték számításakor nem feltétlenül a hívások darabszámát
vagy idejét érdemes használni, hanem két ügyfél kapcsolati erősségét
inkább a közös hívottak számával, vagy két hívott csoport által
meghatározott vektorok által bezárt szöggel érdemes súlyozni.
Kulcsszavak: szociális hálózatok, klaszteranalízis
IRODALOM
Albert Réka – Jeon, H. – Barabási A-L.
(1999): Diameter of the World Wide Web. Nature. 401, 130–131.
Barabási Albert-László (2002): Linked.
Perseus Publishing
Barabási Albert-László – Albert, R. –
Jeong, H. (2000): Scalefree Characteristics of Random Networks: The
Topology of the Word-Wide Web. Physica A. 281, 69–77.
Benczúr András A. – Siklósi D. – Szabó J.
– Bíró I. – Fekete Z. – Kurucz M. –Pereszlényi A. – Rácz S. – Szabó A.
(2008): Web Spam: A Survey with Vision for the Archivist. In:
Proceedings of the International Web Archiving Workshop.
WEBCÍM >
Derényi Imre – Palla G. – Vicsek T.
(2005): Clique Percolation in Random Networks. Physical Review
Letters. 94, 49–60.
WEBCÍM >
Kleinberg, Jon (2000): Navigation in a
Small World. Nature. 406, 845.
Kurucz M. – Siklósi D. – Lukács L. –
Benczúr A. A. – Csalogány K. – Lukács A. (2008): Telephone Call
Network Data Mining: A Survey with Experiments. In: Handbook of
Large-Scale Random Networks. Springer Verlag in conjunction with the
Bolyai Mathematical Society of Budapest
Milgram, Stanley (1967): The Small World
Problem. Psychology Today. 2, 1, 60–67.
Watts, Duncan J. – Strogatz Steven H.
(1998): Collective Dynamics of Small-World’ Networks. Nature. 393,
6684, 440–442.
Zhu, Xiaojin (2005): Semi-supervised
Learning Literature Survey. Technical Report. 1530, Computer Sciences,
University of Wisconsin-Madison
WEBCÍM >
WebSpamChallenge:
\texttt{http://webspam.lip6.fr/}
Weka nyílt forráskódú gépi tanulási
eszköz:
WEBCÍM >
* A TEXTREND NKFP-07-A2 és
az OTKA NK 72845 támogatásával.
<
|